
Natural Language Processing (NLP) is a subfield of artificial intelligence (AI) that focuses on the interaction between computers and human language. It enables machines to understand, interpret, and generate human language in a way that is both meaningful and valuable. NLP has applications in various domains, including machine translation, chatbots, sentiment analysis, and information retrieval. To effectively work in NLP, one must grasp a range of methods and techniques.
Here I am going to give little insights in to the fundamental NLP methods and techniques:
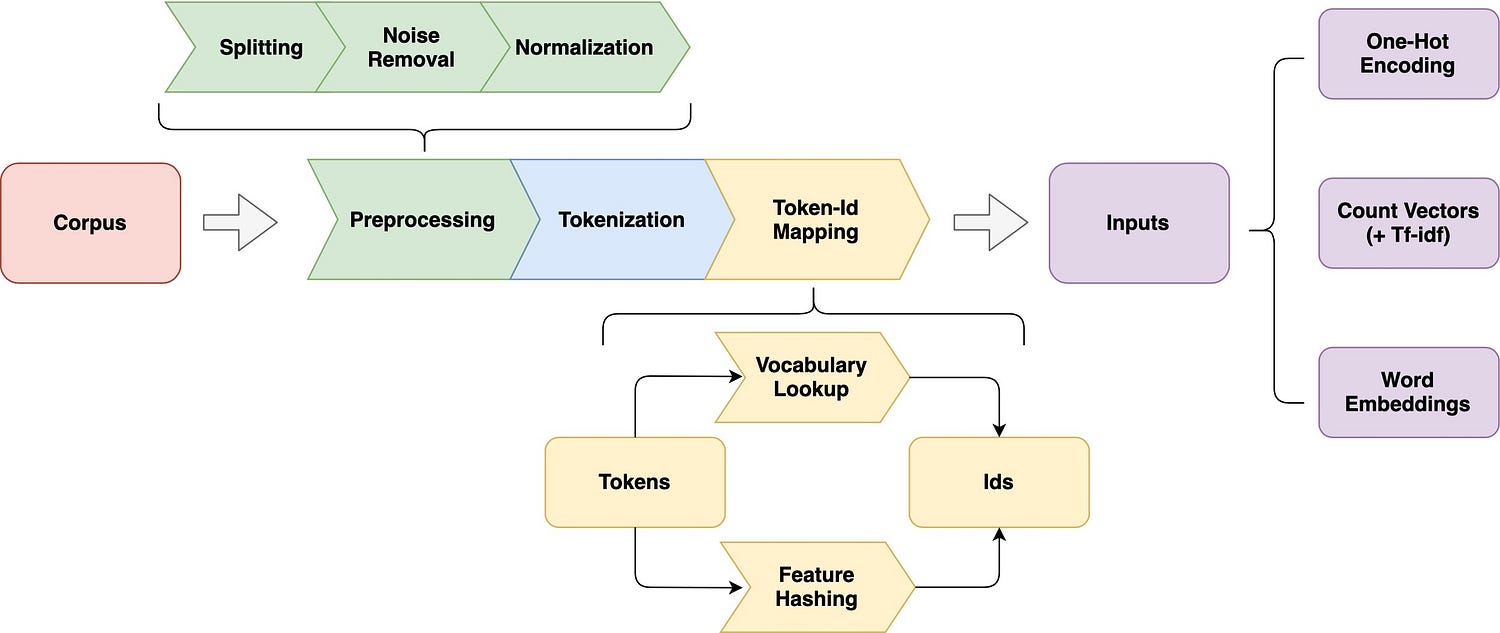
First, let’s compare fundamental NLP methods and techniques as per their features and scopes:
| NLP Methods/Techniques | Scope |
|---|---|
| Text Preprocessing | Text preprocessing involves cleaning and preparing raw text data, making it suitable for NLP tasks. This includes tokenization (breaking text into words or subword units), stopwords removal (filtering out common but insignificant words), and stemming or lemmatization (reducing words to their base forms). These steps improve the quality and consistency of the text data. |
| Text Representation | Text representation is the process of converting raw text data into numerical formats that machine learning models can process. Common methods include Bag of Words (BoW) and TF-IDF for creating word vectors, as well as word embeddings like Word2Vec, GloVe, and contextual embeddings like BERT, which capture the semantic meaning of words and phrases in dense vector representations. These representations facilitate the extraction of patterns and meaning from text. |
| Feature Engineering | Feature engineering in NLP aims to enhance the information extracted from text data. This includes creating n-grams (sequences of words or characters), part-of-speech tagging (labeling words with their grammatical categories), named entity recognition (identifying and classifying entities in text), and sentiment analysis (determining the emotional tone of text, e.g., positive, negative, neutral). Feature engineering enables deeper analysis of text and extraction of valuable information. |
| Text Classification | Text classification involves assigning predefined categories or labels to text data. It is commonly used for tasks like sentiment analysis, spam detection, and document categorization. Text classification can be achieved using various algorithms, ranging from traditional methods like Naive Bayes and Support Vector Machines to advanced deep learning models that leverage convolutional neural networks (CNNs), recurrent neural networks (RNNs), and transformer-based architectures. Text classification is fundamental for automating the organization and understanding of textual content. |
| Language Models | Language models are designed to understand and generate human-like text. Pre-trained models like BERT, GPT-3, and RoBERTa have gained prominence. These models are trained on vast amounts of text data and can be fine-tuned for specific NLP tasks, achieving state-of-the-art performance in areas such as natural language understanding, question answering, and text generation. Language models are a cornerstone of modern NLP, revolutionizing the field. |
| Sequence-to-Sequence Models | Sequence-to-sequence models are essential for handling tasks that involve sequences of input and output. These models, including encoder-decoder architectures and transformer-based models, are used in machine translation, text summarization, and chatbot development. They rely on attention mechanisms to focus on relevant parts of the input sequence, making them suitable for various sequence-to-sequence tasks. |
| Text Generation | Text generation encompasses the creation of coherent and contextually relevant text. It spans a wide range, from simple rule-based systems that generate text character by character or word by word to advanced generative adversarial networks (GANs) that generate text data through adversarial training of generator and discriminator networks. Text generation is used in applications like chatbots, content generation, and creative writing. |
| Named Entity Recognition (NER) | Named Entity Recognition (NER) is the process of identifying and classifying entities within text, such as names of people, organizations, locations, and more. Techniques for NER include conditional random fields (CRF) and deep learning models that can detect and label entities within textual data. NER is essential for information extraction and categorization in various applications. |
| Topic Modeling | Topic modeling is used to discover latent topics within a collection of documents. Common techniques include Latent Dirichlet Allocation (LDA) and Non-Negative Matrix Factorization (NMF). These methods can automatically categorize and extract topics from unstructured text, making it easier to organize and understand large text corpora. |
| Ethical Considerations | Ethical considerations in NLP involve ensuring the responsible use of NLP technologies. This includes addressing issues of bias, fairness, transparency, privacy, and accountability in the development and deployment of NLP applications. Ethical considerations are paramount in creating technology that benefits society and respects individuals’ rights and values. |
import nltk
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
from nltk.stem import PorterStemmer
nltk.download('stopwords')
nltk.download('punkt')
text = "Natural language processing is fascinating!"
# Tokenization
tokens = word_tokenize(text)
# Stopword Removal
filtered_tokens = [word for word in tokens if word.lower() not in stopwords.words('english')]
# Stemming
stemmer = PorterStemmer()
stemmed_tokens = [stemmer.stem(word) for word in filtered_tokens]
print(tokens)
print(filtered_tokens)
print(stemmed_tokens)
from sklearn.feature_extraction.text
import CountVectorizer, TfidfVectorizer
corpus = ["This is the first document.", "This document is the second document."]
# Bag of Words (BoW)
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(corpus)
print(vectorizer.get_feature_names_out())
print(X.toarray())
# TF-IDF
tfidf_vectorizer = TfidfVectorizer()
X_tfidf = tfidf_vectorizer.fit_transform(corpus)
print(tfidf_vectorizer.get_feature_names_out())
print(X_tfidf.toarray())
[Feature Engineering](https://www.analyticsvidhya.com/blog/2021/04/a-guide-to-feature-engineering-in-nlp/):
from nltk.util import ngrams
text = "Natural language processing is fascinating!"
n = 2
bigrams = list(ngrams(text.split(), n))
print(bigrams)
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# Prepare data
X = ["This is a positive review", "This is a negative review", "An example of a positive text", "A negative sentiment here"]
y = [1, 0, 1, 0]
# Vectorize text
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(X)
# Split data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# Train Naive Bayes classifier
clf = MultinomialNB()
clf.fit(X_train, y_train)
# Make predictions
y_pred = clf.predict(X_test)
# Calculate accuracy
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
from transformers import BertTokenizer, BertForSequenceClassification
import torch
# Load pre-trained BERT model and tokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertForSequenceClassification.from_pretrained('bert-base-uncased')
# Tokenize and predict
text = "This is a sample text for sentiment analysis."
inputs = tokenizer(text, return_tensors='pt', padding=True, truncation=True)
outputs = model(**inputs)
print(outputs.logits)
from transformers import GPT2LMHeadModel, GPT2Tokenizer
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
model = GPT2LMHeadModel.from_pretrained("gpt2")
input_text = "How does climate change affect"
input_ids = tokenizer.encode(input_text, return_tensors="pt")
output = model.generate(input_ids, max_length=50, num_return_sequences=1, no_repeat_ngram_size=2, top_k=50)
response = tokenizer.decode(output[0], skip_special_tokens=True)
print(response)
import random
text = "Natural language processing is fascinating!"
words = text.split()
word_pairs = [(words[i], words[i + 1]) for i in range(len(words) - 1)]
start_word = random.choice(words)
generated_text = [start_word]
for _ in range(10):
next_word = random.choice([pair[1] for pair in word_pairs if pair[0] == start_word])
generated_text.append(next_word)
start_word = next_word
print(" ".join(generated_text))
Named Entity Recognition (NER):
import nltk
from nltk import word_tokenize, pos_tag, ne_chunk
nltk.download('maxent_ne_chunker')
nltk.download('words')
text = "Barack Obama was born in Hawaii."
words = word_tokenize(text)
tags = pos_tag(words)
tree = ne_chunk(tags)
print(tree)
from gensim import corpora, models
documents = ["Machine learning is a subfield of artificial intelligence.",
"Natural language processing is a crucial component of NLP.",
"Deep learning has revolutionized the field of AI."]
# Tokenize and create a dictionary
texts = [doc.split() for doc in documents]
dictionary = corpora.Dictionary(texts)
# Create a corpus
corpus = [dictionary.doc2bow(text) for text in texts]
# Build an LDA model
lda_model = models.LdaModel(corpus, num_topics=2, id2word=dictionary)
# Print topics
for topic in lda_model.print_topics():
print(topic)
NLP is a dynamic field with rapid advancements. Mastering NLP methods and techniques requires a combination of theoretical knowledge and practical experience. As you delve deeper into NLP, you’ll discover a wide range of applications and use cases, making it an exciting and evolving field within AI.
In conclusion, natural language processing (NLP) is a multifaceted field within artificial intelligence that encompasses a wide range of methods and techniques to enable computers to understand, interpret, and generate human language. Each NLP task plays a vital role in the processing and analysis of text data, serving distinct purposes in various applications.
Text Preprocessing forms the foundation by cleaning and preparing text data for analysis.
Text Representation translates text into numerical formats for machine learning models to work with effectively.
Feature Engineering enriches text data by creating additional information for analysis.
Text Classification categorizes text into predefined classes, making it useful for tasks like sentiment analysis or topic classification.
Language Models leverage pre-trained models to understand and generate human-like text, revolutionizing NLP capabilities.
Sequence-to-Sequence Models are essential for tasks that involve input and output sequences, such as machine translation and chatbot development.
Text Generation enables the creation of coherent and contextually relevant text, ranging from rule-based to GAN-based systems.
Named Entity Recognition (NER) identifies and categorizes entities within text, supporting information extraction.
Topic Modeling uncovers latent topics in a collection of documents, aiding in text organization and understanding.
Ethical Considerations emphasize the responsible development and deployment of NLP technologies, addressing ethical issues like bias, fairness, and privacy.
NLP is a dynamic and evolving field, with constant advancements in algorithms and models, making it a crucial component of many AI applications. Understanding the scope and purpose of each NLP task is fundamental for harnessing the power of NLP in various domains, from healthcare to finance, education, and beyond. As the field continues to progress, it is essential to remain conscious of ethical considerations, ensuring that NLP technologies are developed and used in ways that benefit society while respecting individual rights and values.
Text Preprocessing:
Text Representation:
Feature Engineering:
Text Classification:
Language Models:
Sequence-to-Sequence Models:
Text Generation:
Named Entity Recognition (NER):
Topic Modeling:
Ethical Considerations:
These resources offer in-depth knowledge and hands-on experience in various NLP tasks, feature engineering, ethical considerations, and more. They range from books and courses to research papers and online documentation, providing a diverse set of learning materials for those looking to explore NLP thoroughly.

“Fine-tuning” means adapting an existing machine learning model for specific tasks or use cases. In this post I’m going to walk you through how you can fine tune a large language model for sentence similarity using some hand annotated test data. This example is in the psychology domain. You need training data consisting of pairs of sentences, and a “ground truth” of how similar you want those sentences to be when you train your custom sentence similarity model.

Hire an NLP developer and untangle the power of natural language in your projects The world is buzzing with the possibilities of natural language processing (NLP). From chatbots that understand your needs to algorithms that analyse mountains of text data, NLP is revolutionising industries across the board. But harnessing this power requires the right expertise. That’s where finding the perfect NLP developer comes in. Post a job in NLP on naturallanguageprocessing.

Natural language processing What is natural language processing? Natural language processing, or NLP, is a field of artificial intelligence that focuses on the interaction between computers and humans using natural language. NLP is a branch of AI but is really a mixture of disciplines such as linguistics, computer science, and engineering. There are a number of approaches to NLP, ranging from rule-based modelling of human language to statistical methods. Common uses of NLP include speech recognition systems, the voice assistants available on smartphones, and chatbots.
